들어가며
안녕하세요. 현재 크래프톤 정글에서 "넌! 런"이라는 러닝앱을 개발하고 있습니다. 핵심 기능 개발이 끝나고 나서 서버 성능 테스트를 해보고 한계를 확인하고 이를 개선하고자 공부한 내용을 글로 남기고자 합니다.
초기 아키텍처

초기엔 개발이 급선무였기에 최대한 아키텍처를 잘 짜고 싶다는 사심을 배제해서 구성했습니다. 단일 인스턴스로 구축되었으며 HTTPS SSL/TLS 통신은 nginx가 담당하고 있었습니다. CI/CD는 Github Actions을 이용해서 Develop 브랜치에 코드가 머지가 되면 AWS ECR에 Docker Image를 저장하고 인스턴스에 ssh 접속해서 pull 해서 컨테이너를 올리는 방식으로 진행했습니다. 이 과정 속에서 nginx 또한 관리해야하므로 Docker Compose를 이용했습니다.
그림 1 아키텍처를 잘 쓰고 있다가 핵심 기능을 개발이 끝나고 나서 미뤄두었던 부하 테스트를 진행했습니다.
초기 아키텍처 부하 테스트
기존에 프리 티어인 t2.micro를 쓰다가 크레딧이 생겨서 스케일업한 t2.small 인스턴스를 사용했기 때문에 한계가 어디까지인지 테스트부터 필요했습니다.
그래서 Jmeter "Concurrency Thread Group" 플러그인 중 “Stepping Thread Group”과 "3 Basic Graphs" 플러그인을 사용해서 단계별로 사용자의 흐름을 만들어서 테스트해보기로 했습니다. 단순히 강제로 부하를 걸기보다는 세부적인 시나리오로 부하를 주는 것이 정확히 어디까지 이 서버가 감당가능한지 알 수 있을 것 같아 진행했습니다.
테스트 시나리오

10명씩 30초마다 추가 투입(단, 1초에 6명씩 투입해서 단계적으로 증가) → 투입 후 30초 유지 → 300명도달 시 1분 유지 → 1초마다 5명씩 감소
테스트할 엔드포인트는 가장 부하가 클 것으로 예상되는 11km 길이의 경로 GPS 배열 불러오기입니다.
저희 서비스의 핵심 기능으로 DB에 저장된 공공데이터 트랙을 사용자에게 제공합니다. 그 중에선 24km 길이의 경로 GPS 배열이 있고 이는 JVM 메모리와 Network 부하에 큰 영향이 있을 것이라고 판단하여 선택하였습니다.
부하 테스트 결과

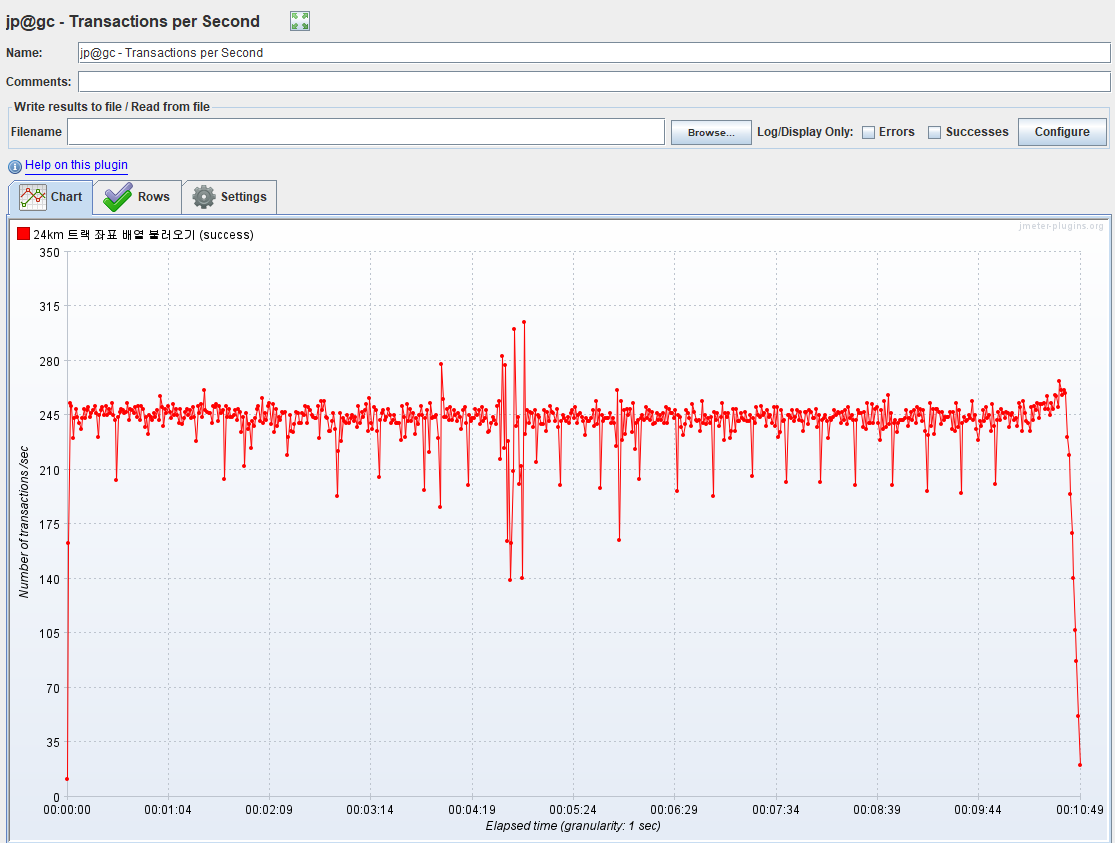


평균 응답 속도는 0.8초, 최대 응답 속도는 7.8초로 나왔습니다.
T 타입 인스턴스에서 작동하는 CPUCreditBalance가 급격히 떨어지는 성능 절벽 현상과 CPU 사용량이 약 99.8%까지 올라가는 문제가 있었습니다.
최대 인원이 300명까지는 에러율이 생기진 않았지만 충분히 성능 저하가 있다고 판단하여 캐시를 도입해서 성능을 올리기로 결정했습니다.
어떤 캐시를 사용해야 하는가?(Redis VS Valkey)
이전까지만 하더라도 Redis의 존재만 알고 있었습니다.
그러나, AWS ElastiCache를 사용하기 위해 홈페이지가 들어가니 다음과 같은 친구가 반겨주었습니다.

매우 구미가 땡기는 모달이었는데, 비용 절감과 오픈 소스, 거기다가 기존 Redis와 완벽한 호환을 강조하고 있는 겁니다.
그래서 찾아보았습니다. Valkey가 어떤 친구며, 왜 탄생하게 됐는지를 말입니다.
Valkey 유래
사건의 시작은 2024년 Redis의 라이센스 변경으로부터 도래됐습니다.
상업적 사용에 제약이 있는 BSL로 변경되면서 여러 글로벌 빅테크 기업과 커뮤니티가 협력해서 만든 완전 오픈소스입니다.
Redis 버전 7.2.4 로부터 포크된 것으로 알려져 있습니다.
Valkey 8.0이 발표되고 기존의 버전과 비교하여 읽기/쓰기 처리 성능, 메모리 효율성 등 성능이 향상되고 다양한 기능이 추가되었습니다.
그러면 Valkey가 Redis에 비해 얼마나 저렴한가요?


AWS ElastiCache 기준으로 약 25% Valkey가 저렴합니다.
사용하지 않을 수 없었기에 바로 Valkey를 선택하게 되었습니다.
캐시를 어디에 도입해야 하는가?
캐시를 어떤 걸 사용할 지 정했으니, 어디에 이 캐시를 도입을 할 지가 문제였습니다.
TrackInfoDto trackInfoDto = TrackInfoDto.convertToResponseDto(track);
public record TrackInfoDto(
List<CoordinateDto> path,
int totalDistance,
String name,
double rate
) {
public static TrackInfoDto convertToResponseDto(RunningTrack track) {
List<CoordinateDto> path = CoordinateConverter.convertLineStringToCoordinates(track.getPath());
return new TrackInfoDto(
path,
track.getTotalDistance(),
track.getName(),
track.getRate()
);
}
}실제로 LineString으로 표현되어있던 긴 트랙의 배열을 다시 원래대로 돌리는 부분이 연산 및 메모리 부하가 클 것으로 예상이 되어 이 메서드를 캐시 처리하기로 했습니다.
다만, 모든 트랙을 다 캐시를 하면 캐시 서버 부하가 심해지기 때문에, 10km 넘는 트랙에만 캐시를 적용하도록 했습니다.
@Service
@RequiredArgsConstructor
public class TrackInfoService {
private final TrackRepository trackRepository;
@Cacheable(value = "track-info", key = "#trackId")
public TrackInfoDto getCacheTrackInfo(Long trackId) {
RunningTrack track = trackRepository.findById(trackId)
.orElseThrow(() -> new ApiException(ErrorCode.TRACK_NOT_EXIST));
return TrackInfoDto.convertToResponseDto(track);
}
public TrackInfoDto getTrackInfo(Long trackId){
RunningTrack track = trackRepository.findById(trackId)
.orElseThrow(() -> new ApiException(ErrorCode.TRACK_NOT_EXIST));
return TrackInfoDto.convertToResponseDto(track);
}
}int trackTotalDistance = trackRepository.findTotalDistanceById(trackId)
.orElseThrow(() -> new ApiException(ErrorCode.TRACK_NOT_EXIST));
TrackInfoDto trackInfoDto;
if (trackTotalDistance >= TRACK_CACHE_TOTAL_DISTANCE_STANDARD){
trackInfoDto = trackInfoService.getCacheTrackInfo(trackId);
} else {
trackInfoDto = trackInfoService.getTrackInfo(trackId);
}
도입 결과..?
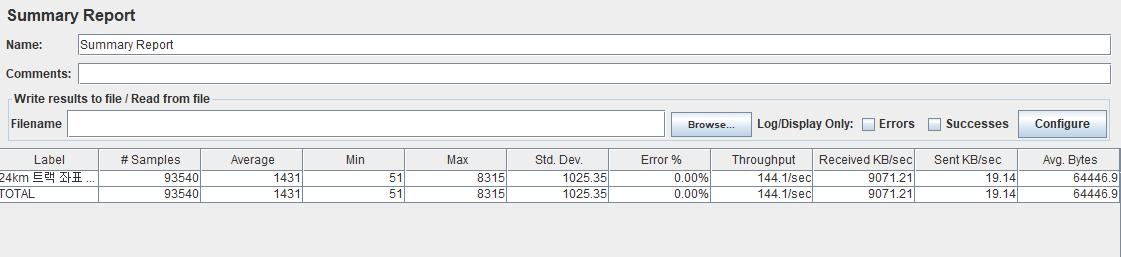
아리송하게 오히려 더 응답속도가 느려졌습니다.
서버에 문제가 있는지부터 로그를 봤는데 아니나다를까 에러가 마중해주네요.
2025-08-02T18:40:19.270Z ERROR 1 --- [you-run] [o-8080-exec-208] c.r.y.g.e.GlobalExceptionHandler : 예상치 못한 예외 발생: URI=/api/track, Exception=ServletOutputStream failed to write: java.io.IOException: Broken pipe
org.springframework.web.context.request.async.AsyncRequestNotUsableException: ServletOutputStream failed to write: java.io.IOException: Broken pipe
at org.springframework.web.context.request.async.StandardServletAsyncWebRequest$LifecycleHttpServletResponse.handleIOException(StandardServletAsyncWebRequest.java:346) ~[spring-web-6.2.8.jar!/:6.2.8]
....
Caused by: java.io.IOException: Broken pipe
at java.base/sun.nio.ch.FileDispatcherImpl.write0(Native Method) ~[na:na]
at java.base/sun.nio.ch.SocketDispatcher.write(SocketDispatcher.java:62) ~[na:na]
at java.base/sun.nio.ch.IOUtil.writeFromNativeBuffer(IOUtil.java:132) ~[na:na]
at java.base/sun.nio.ch.IOUtil.write(IOUtil.java:97) ~[na:na]
at java.base/sun.nio.ch.IOUtil.write(IOUtil.java:53) ~[na:na]
at java.base/sun.nio.ch.SocketChannelImpl.write(SocketChannelImpl.java:532) ~[na:na]
at org.apache.tomcat.util.net.NioChannel.write(NioChannel.java:125) ~[tomcat-embed-core-10.1.42.jar!/:na]
at org.apache.tomcat.util.net.NioEndpoint$NioSocketWrapper.doWrite(NioEndpoint.java:1411) ~[tomcat-embed-core-10.1.42.jar!/:na]
at org.apache.tomcat.util.net.SocketWrapperBase.doWrite(SocketWrapperBase.java:732) ~[tomcat-embed-core-10.1.42.jar!/:na]
at org.apache.tomcat.util.net.SocketWrapperBase.writeBlocking(SocketWrapperBase.java:572) ~[tomcat-embed-core-10.1.42.jar!/:na]
at org.apache.tomcat.util.net.SocketWrapperBase.write(SocketWrapperBase.java:520) ~[tomcat-embed-core-10.1.42.jar!/:na]
at org.apache.coyote.http11.Http11OutputBuffer$SocketOutputBuffer.doWrite(Http11OutputBuffer.java:548) ~[tomcat-embed-core-10.1.42.jar!/:na]
at org.apache.coyote.http11.filters.IdentityOutputFilter.doWrite(IdentityOutputFilter.java:84) ~[tomcat-embed-core-10.1.42.jar!/:na]
at org.apache.coyote.http11.Http11OutputBuffer.doWrite(Http11OutputBuffer.java:193) ~[tomcat-embed-core-10.1.42.jar!/:na]
at org.apache.coyote.Response.doWrite(Response.java:628) ~[tomcat-embed-core-10.1.42.jar!/:na]
at org.apache.catalina.connector.OutputBuffer.realWriteBytes(OutputBuffer.java:330) ~[tomcat-embed-core-10.1.42.jar!/:na]
... 166 common frames omitted
왜 I/O Broken Pipe가 뜨지 곰곰이 고민해봤습니다.

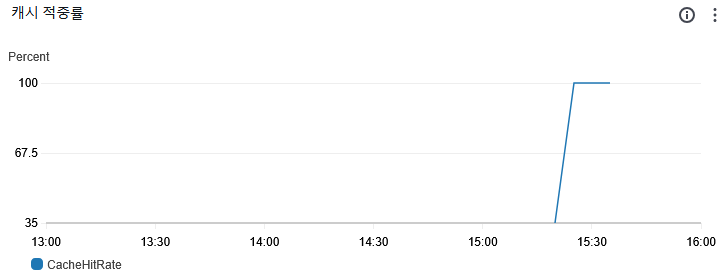
유력한 범인은 Cache와 관련이 있을 거 같아서 확인해봤는데 캐시에 데이터 저장은 문제가 없었고 캐시 히트도 100%이었습니다.
그렇다면 캐시에 저장되어 있는 너무 긴 트랙의 배열이 문제라고 판단했습니다.
I/O Broken Pipe는 타임아웃등의 이유로 연결되지 않은 소켓에 접속해서 발생하는 에러로 너무 큰 배열의 데이터를 차마 보내기도 전에 소켓이 닫혀서 발생하는 현상이었습니다.
문제 해결이 시급하다
지난 글에서 공부했던 Ramer-Douglas-Peucker (RDP) 알고리즘을 통해서 서버에서 경로를 변환해서 캐시 서버에 저장할 때, 단순화시켜 저장하는 방식으로 데이터의 양을 줄이는 방식으로 접근했습니다.
[Spring]지도 경로 로딩 최적화 문제 해결하기 (feat. PostGIS, Ramer-Douglas-Peucker)
[Spring]지도 경로 로딩 최적화 문제 해결하기 (feat. PostGIS, Ramer-Douglas-Peucker)
들어가며안녕하세요. 현재 크래프톤 정글에서 "넌! 런"이라는 러닝앱을 개발하고 있습니다. GPS를 많이 사용하는 러닝앱 특성상 수많은 좌표들을 최적화하는 문제에 직면하여 고생한 내용을 글
namamim.tistory.com
package com.running.you_run.running.payload.dto;
import com.running.you_run.running.entity.RunningTrack;
import com.running.you_run.running.util.CoordinateConverter;
import org.locationtech.jts.geom.Coordinate;
import org.locationtech.jts.geom.LineString;
import org.locationtech.jts.simplify.DouglasPeuckerSimplifier;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public record TrackInfoDto(
List<CoordinateDto> path,
int totalDistance,
String name,
double rate
) {
...
public static TrackInfoDto convertToSimplifiedResponseDto(RunningTrack track) {
double epsilon = 0.0005;
LineString simplifiedLine = (LineString) DouglasPeuckerSimplifier.simplify(track.getPath(), epsilon);
List<CoordinateDto> path = CoordinateConverter.convertLineStringToCoordinates(simplifiedLine);
return new TrackInfoDto(
path,
track.getTotalDistance(),
track.getName(),
track.getRate()
);
}
}

앱실론 값은 0.0005로 위도와 경도 기준이기에 아주 작은 값을 사용하였고, 결과를 보시면 실제 경로와 큰 차이가 없습니다.
개선한 결과

최대 응답 시간 3.3초, 평균 응답 시간 0.52초 지연 발생으로 캐시 서버와 RDP 알고리즘 도입 이전보다 최대 응답 시간 약57%,
평균 응답 시간 약 37.5% 향상시켰습니다.
'서버 공부 > Spring' 카테고리의 다른 글
| [Spring]heapdump를 이용해서 메모리 누수(Memory Leak) 찾아보기 feat. Eclipse Memory Analyzer (0) | 2025.10.22 |
|---|---|
| [Spring]Google Static Maps API 적용기(지도 로딩 속도 최적화하기) (4) | 2025.08.01 |
| [Spring]지도 경로 로딩 최적화 문제 해결하기 (feat. PostGIS, Ramer-Douglas-Peucker) (8) | 2025.07.12 |
| Spring에서 HTTP 요청이 들어오면 처리되는 전체적인 흐름 (0) | 2025.02.24 |
| [Spring+MongoDB]한 컬렉션에서 중복된 필드값 검증하기(feat. 고유 인덱스) (0) | 2025.02.13 |